Shuzheng Si
 Ph.D. student, Tsinghua University
Ph.D. student, Tsinghua University
Hi, I’m Shuzheng Si, a second-year CS Ph.D. Candidate at Tsinghua University. I am lucky to be advised by Prof. Maosong Sun and affiliated with TsinghuaNLP Lab. Previously, I obtained my master’s degree from Peking University, where I was a part of the PKU NLP Group under the supervision of Prof. Baobao Chang. My research interests lie in Natural Language Processing (NLP) and Large Language Models (LLMs), specifically focusing on Hallucinations in LLMs , including:
- 📖 Hallucination Attribution — Understanding Hallucinations at the Source: My first line of research aims to explore and understand how training data contributes to hallucinations (NOVA, GATEAU, NUGGETS). This line of research mainly focuses on combining both qualitative and quantitative analyses of training data, guiding data collection to reduce LLM hallucinations.
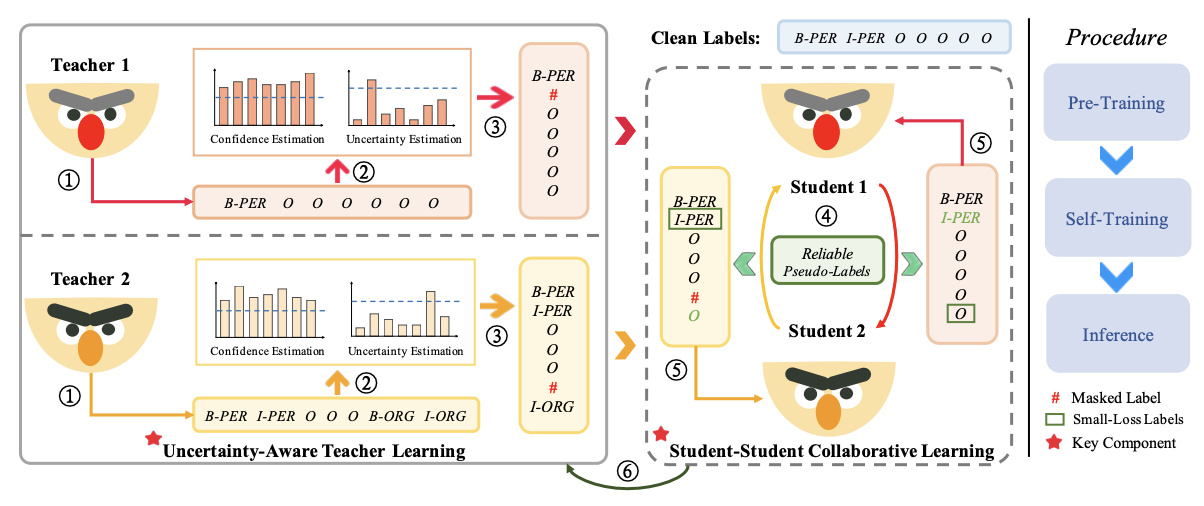
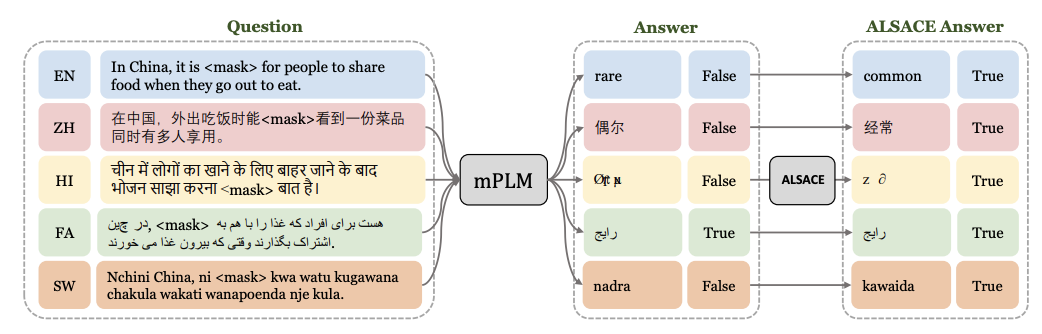
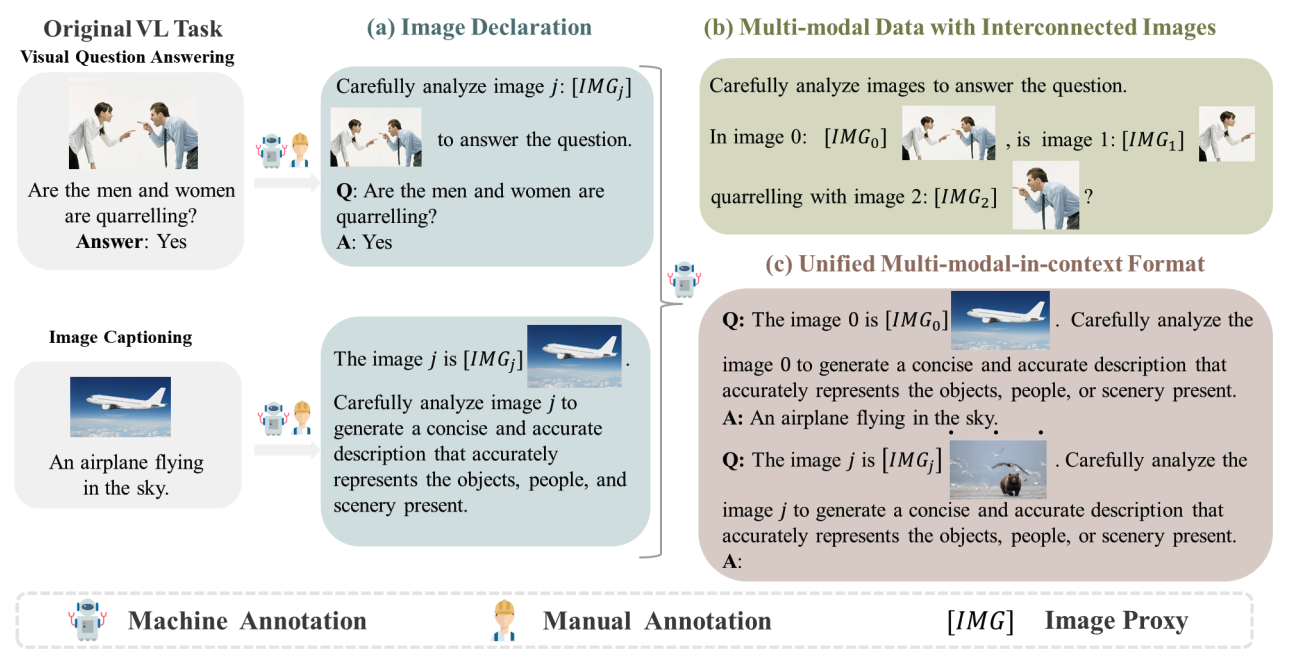
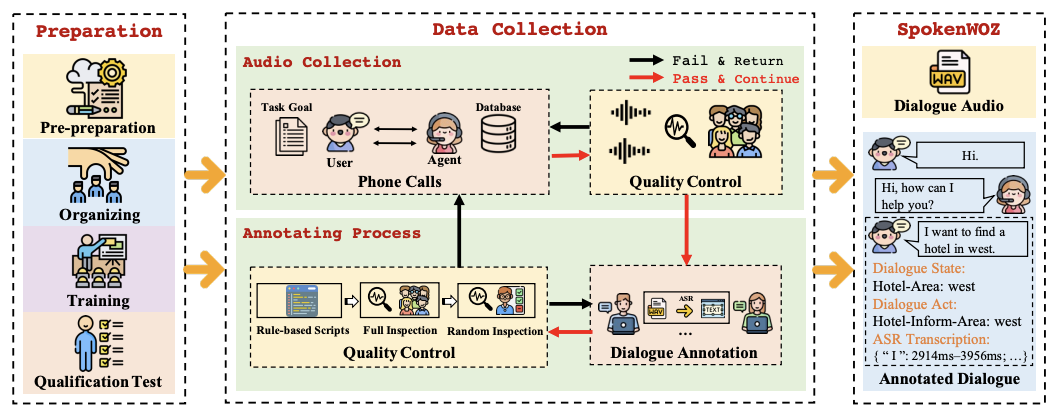
- 🔧 Hallucination Mitigation — Reducing Hallucinations in LLMs: This line of research focuses on designing effective strategies to reduce hallucinations, covering controllable text generation (CANOE, LingoEDU), multi-modal scenarios (MMICL, LACING), and agentic tasks (SpokenWOZ, EAGLET, RhinoInsight). These methods provide practical solutions to reduce hallucinations in real-world applications.
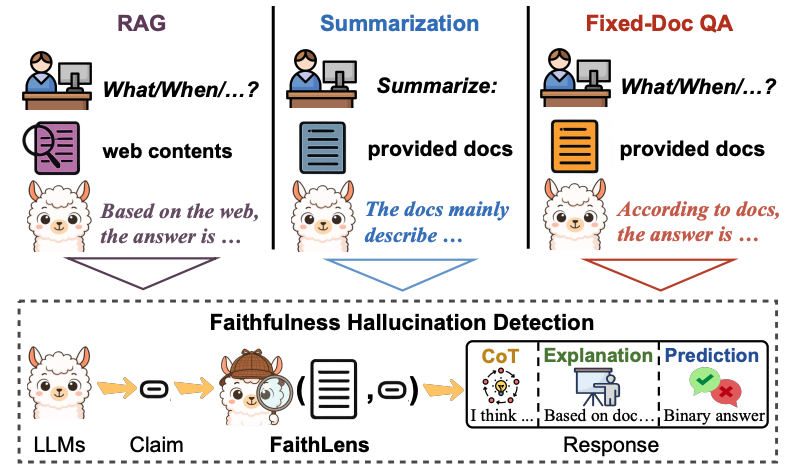
- 🔎 Hallucination Detection — Identifying Hallucinations in the Wild: This research attempts to identify hallucinated responses generated by LLMs and prevent such hallucinated responses from being provided to users (FaithLens). By enabling the timely hallucination detection and practical interventions, LLM-based systems can be more reliable and trustworthy in real-world deployment.
- 🌏 Building Information-Seeking Tools With the Lowest Hallucination Rates: I also apply my research to build real-world information-seeking applications with the lowest hallucination rates, e.g., LingoWhale, RhinoInsight, and Zhiliao News released by DeepLang AI and TsinghuaNLP Lab. To date, these applications have provided trustworthy text processing services to hundreds of thousands of Chinese users.
Education
-
Tsinghua University
Ph.D. in Computer Science and Technology Sep. 2024 - Jul. 2028 (expected)
-

Peking University
M.S. in Software Engineering Sep. 2021 - Jul. 2024
-

Yunnan University
B.S. at the School of Software (Rank: 1/300+) Sep. 2017 - Jul. 2021
Honors & Awards
- CAST’s Young Talents Support Project, Ph.D. Program 2025
- EMNLP SAC Highlights Paper Award 2025
- Comprehensive Excellence Scholarship, THU 2025
- Merit Student, PKU 2022
- Student of the Year Nominee Award (Ranked 1st, YNU) 2020
- National Scholarship 2019
- Provincial Government Scholarship 2018
Experience
-

DeepLang AI
Research Staff Apr. 2024 - Now
-

Alibaba DAMO Academy
Research Intern Jun. 2022 - Jun. 2023
-

SenseTime Research
Research Intern Jul. 2021 - Feb. 2022
Service
- NLP Research Communities: Reviewer of ACL, EMNLP, NAACL, COLING, and TASLP
- ML Research Communities: Reviewer of NeurIPS, ICLR, ICML, and AAAI
- CV Research Communities: Reviewer of ICCV
- I am also a member of the BIRD team, led by the talent researcher Jinyang Li, which drives the development of text-to-SQL for real-world database applications
News
First-Authored Papers (view all papers on Google Scholar )
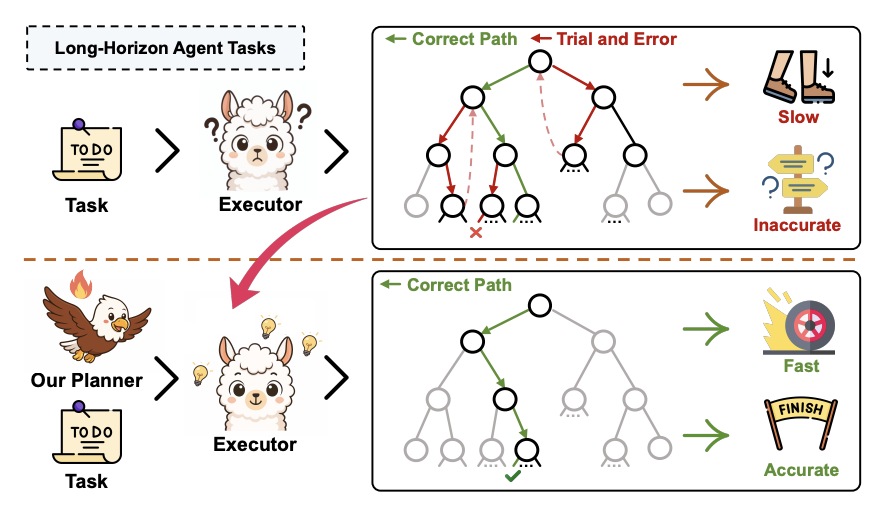
A Goal Without a Plan Is Just a Wish: Efficient and Effective Global Planner Training for Long-Horizon Agent Tasks
Shuzheng Si, Haozhe Zhao, Kangyang Luo, Gang Chen, Fanchao Qi, Minjia Zhang, Baobao Chang, Maosong Sun
Preprint 2025
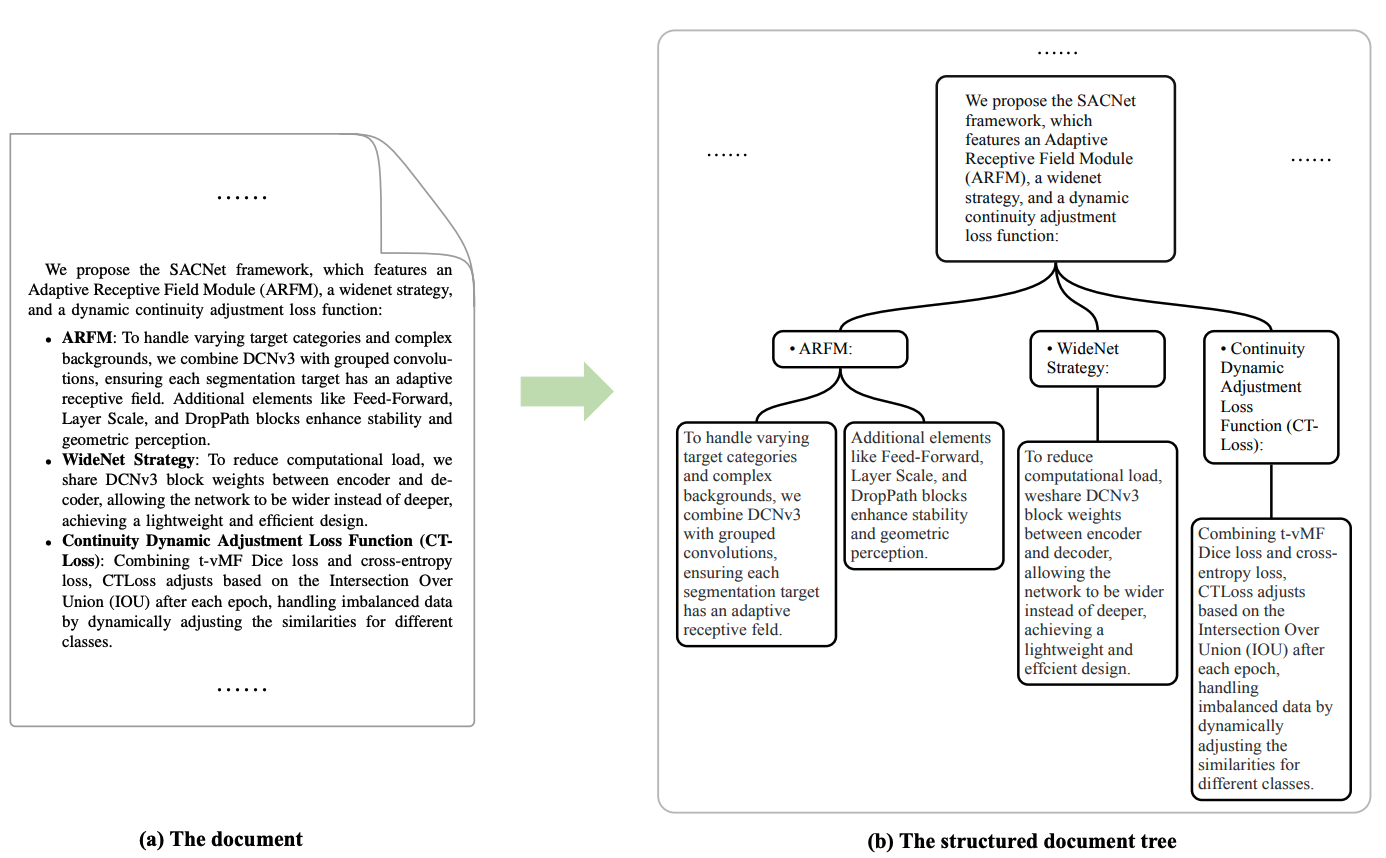
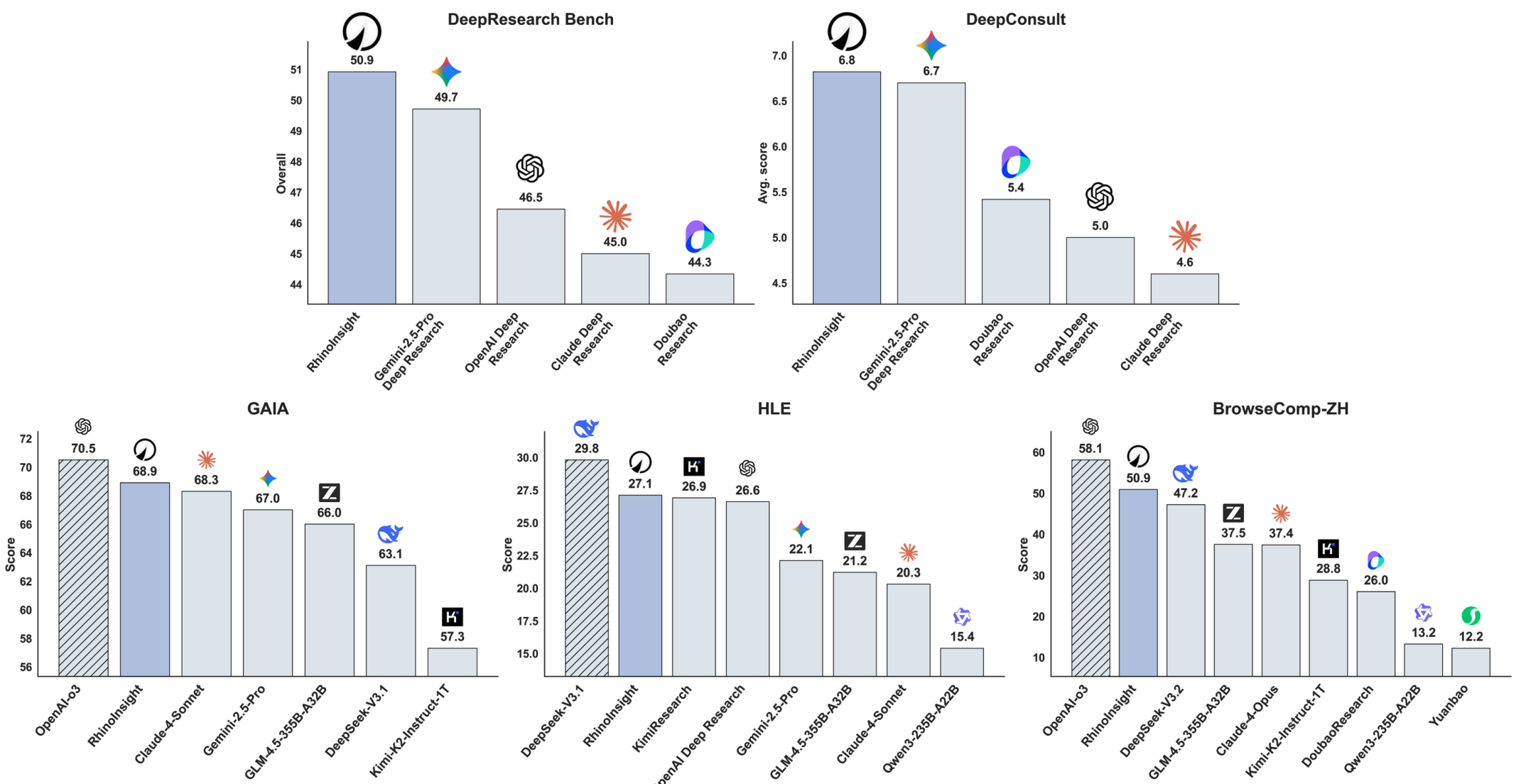
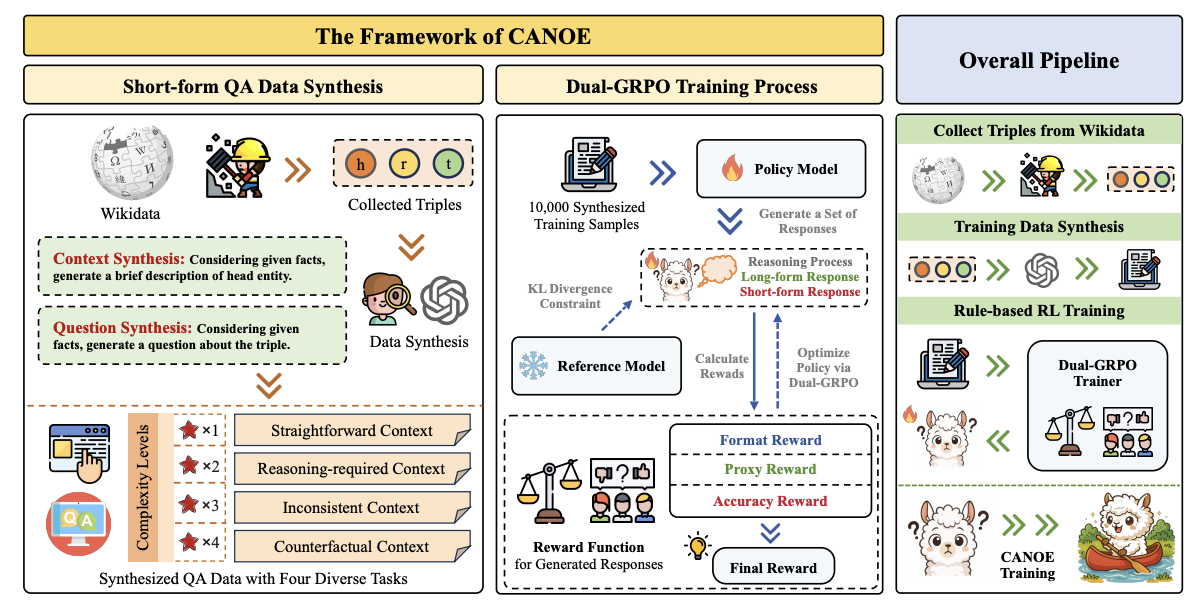
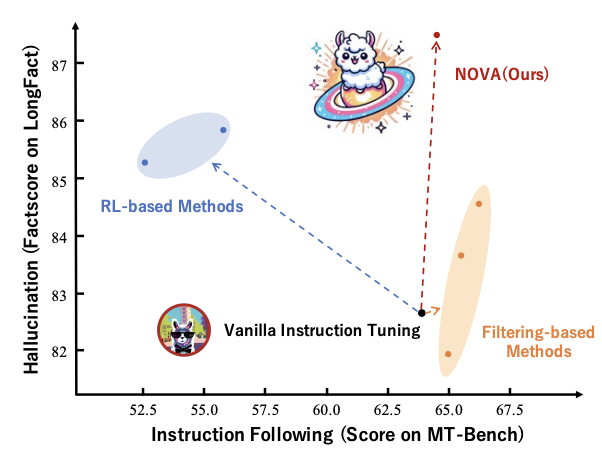
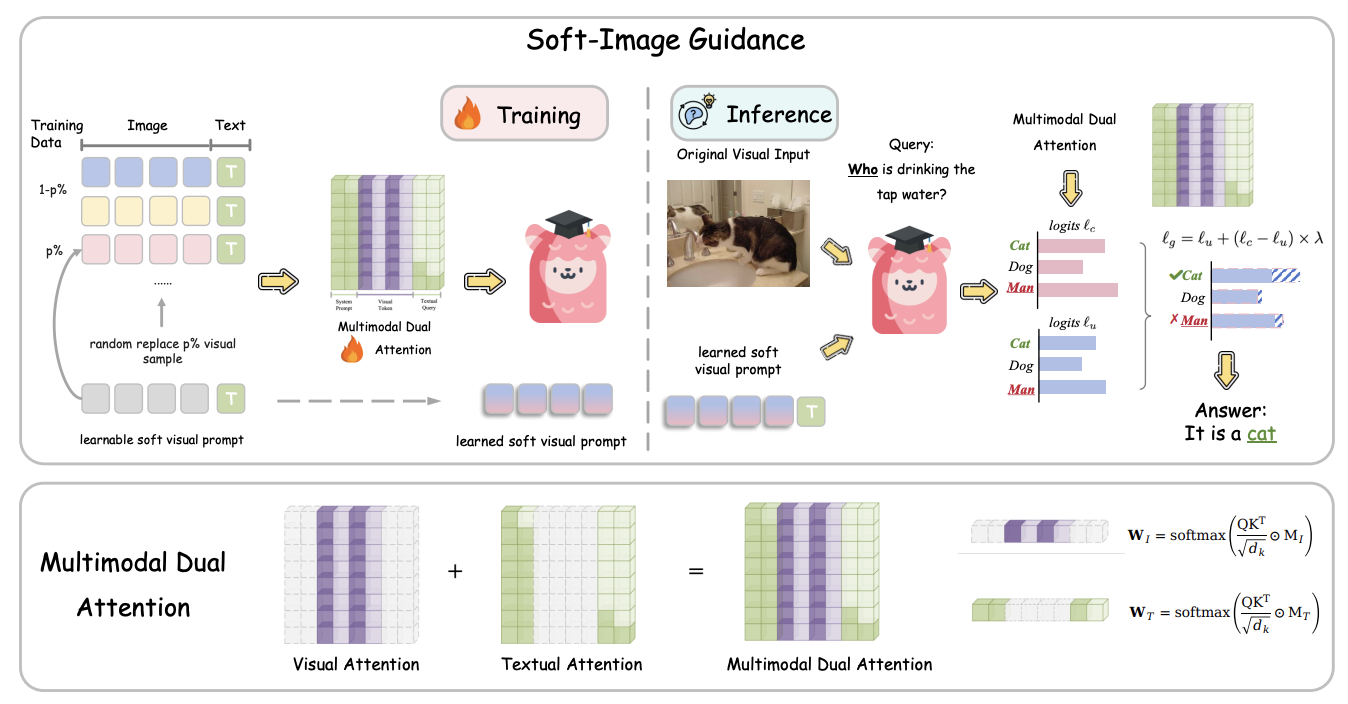
Teaching Large Language Models to Maintain Contextual Faithfulness via Synthetic Tasks and Reinforcement Learning
Shuzheng Si, Haozhe Zhao, Cheng Gao, Yuzhuo Bai, Zhitong Wang, Bofei Gao, Kangyang Luo, Wenhao Li, Yufei Huang, Gang Chen, Fanchao Qi, Minjia Zhang, Baobao Chang, Maosong Sun
AAAI 2026 (Oral), KnowFM@ACL 2025 Workshop (Oral)

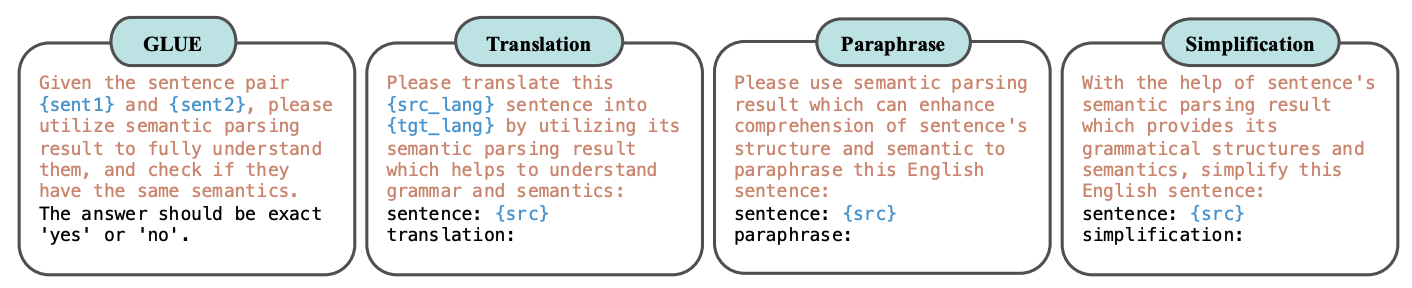
Rethinking Semantic Parsing for Large Language Models: Enhancing LLM Performance with Semantic Hints
Kaikai An*, Shuzheng Si*, Helan Hu, Haozhe Zhao, Yuchi Wang, Qingyan Guo, Baobao Chang
ACL 2025 (* indicates co-first authors)